
Join 1,000s of professionals who are building real-world skills for better forecasts with Microsoft Excel.
Issue #34 - Boosted Decision Trees Part 3:
Python Code
This Week’s Tutorial
This week's tutorial will teach you how the AdaBoost algorithm builds an ensemble of weak learners (i.e., decision stumps) step by step.
If you're new to this tutorial series, be sure to check out Part 2 here, as it is the most important in this series.
If you would like to follow along with today's tutorial (highly recommended), download one of the following two files from the newsletter's GitHub repository:
adult_train.csv
Adult.xlsx
Loading the Data
Here's the code for loading this tutorial's dataset using Python in Excel and Jupyter Notebook:

NOTE - As the code between Python in Excel and Jupyter Notebooks is the same, I will only show Python in Excel going forward in this tutorial.
And the info for the DataFrame:
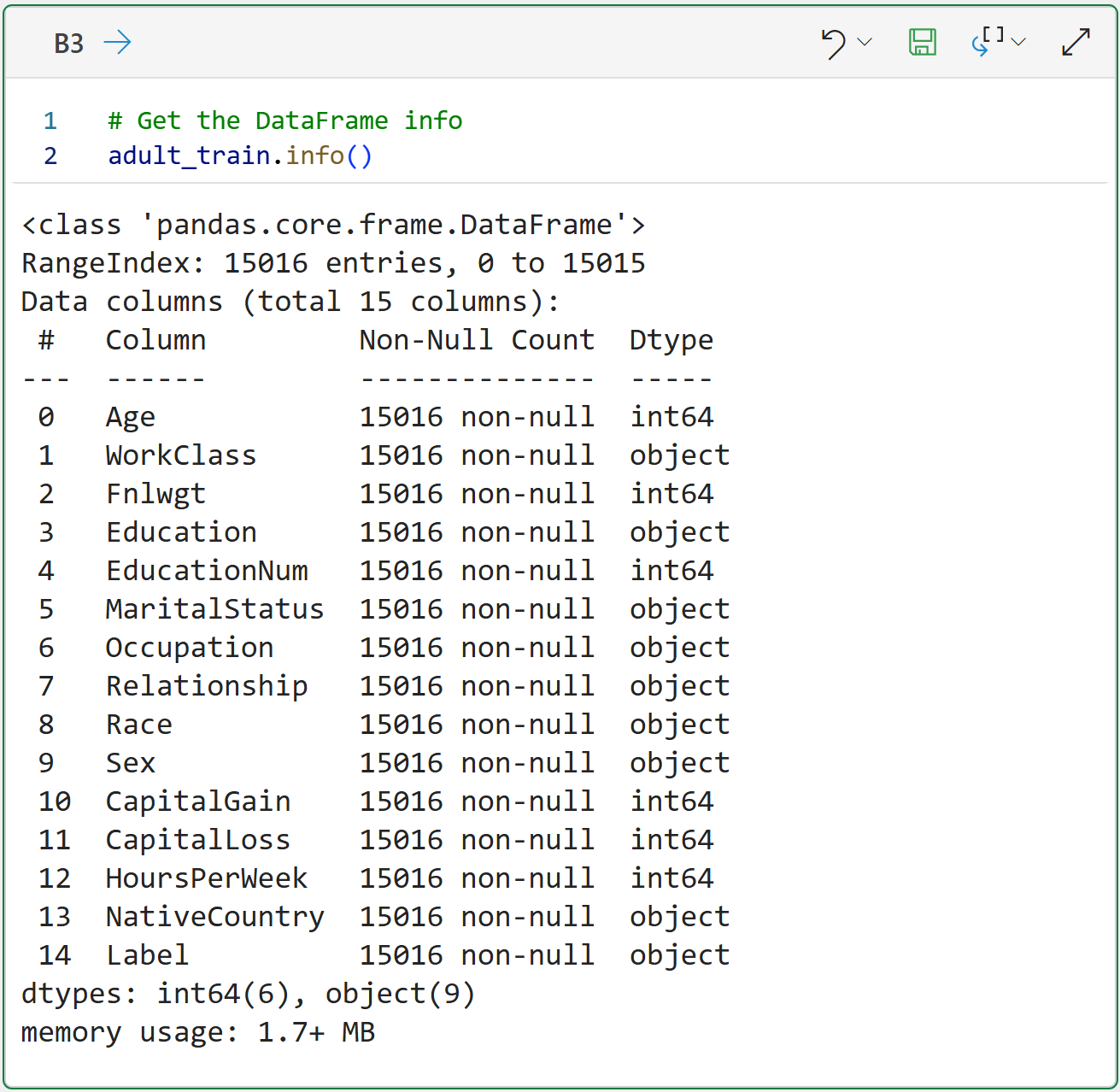
If you're interested, you can learn more about this dataset from the UCI Machine Learning Repository.
For our purposes, this dataset embodies a predictive modeling task where:
Label represents the income of a US resident of either more than $50,000 per year (i.e., Label value of >50K) or less (i.e., Label value of <=50K).
The rest of the features are characteristics of US residents (e.g., Age, Education, HoursPerWeek, etc.)
The AdaBoost algorithm will build an ensemble of weak learners (i.e., decision stumps) to accurately predict Label based on the available features.
For this tutorial, I will be using a subset of the available features to keep things simple:

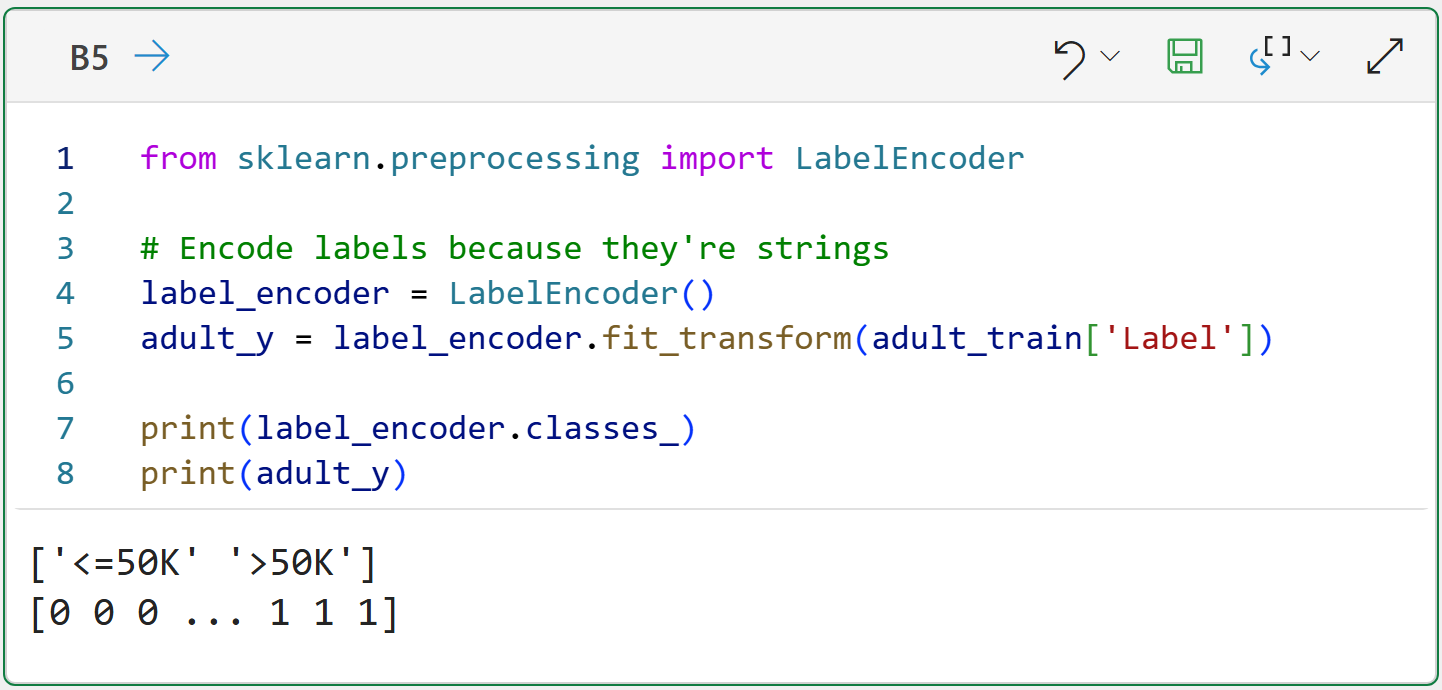
Also, the Label feature consists of string values, so encoding them to be numeric is a good idea:
The classic AdaBoost algorithm takes only one input from you - the number of weak learners in the ensemble. This is often called the number of boosting rounds, as each round produces a weak learner.
For this tutorial, we'll use three boosting rounds to demonstrate how AdaBoost works step by step.
However, this number of boosting rounds may or may not be optimal for the tutorial's dataset. I arbitrarily selected three for this tutorial.
Boosting Round #1
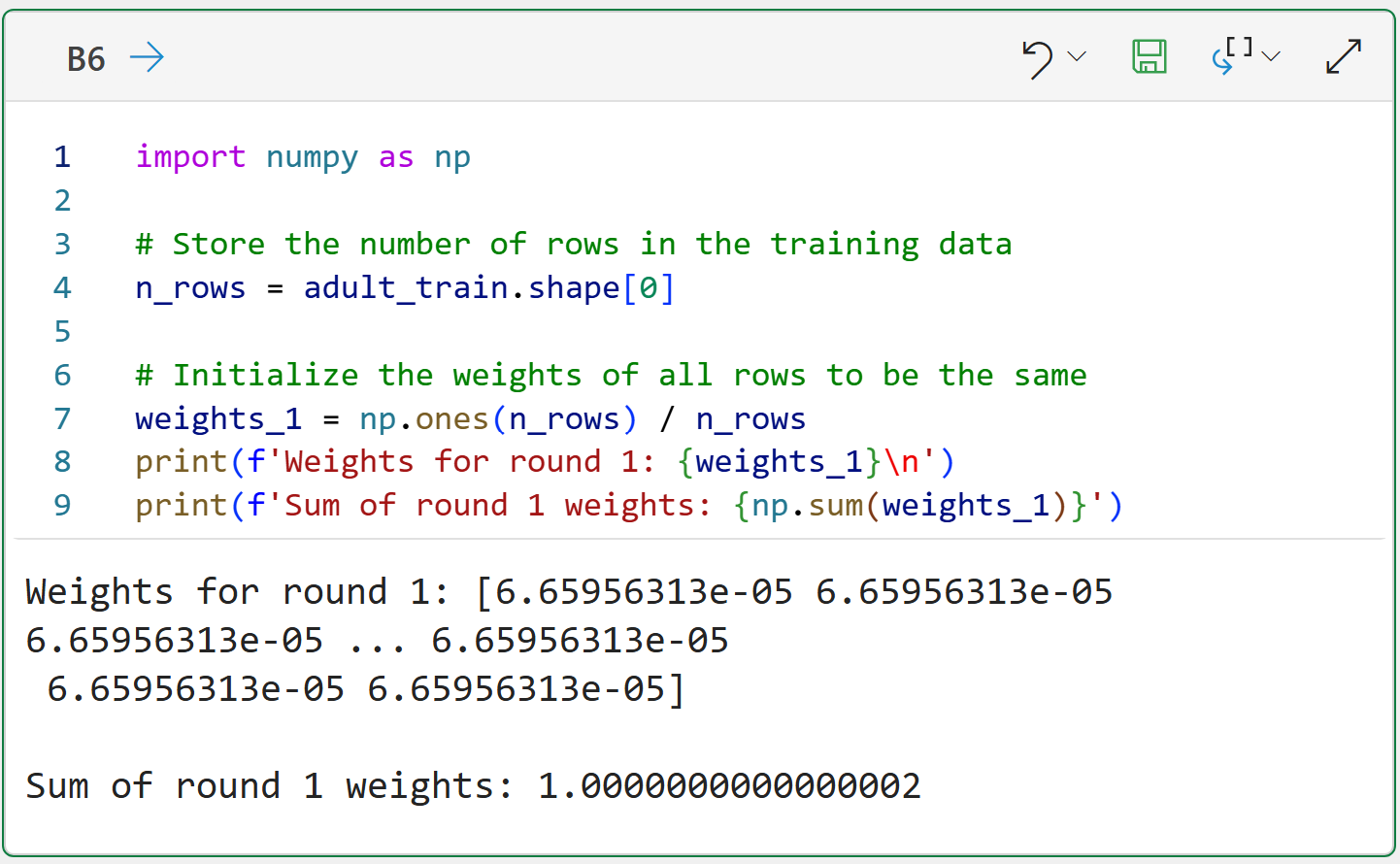
As covered in Part 2 of this tutorial series, the first step in AdaBoost is to create the initial weights for each row in the training dataset, where each weight is the same for Round #1:
With the initial weights calculated, the next step is to train a weak learner. In the case of the classic AdaBoost algorithm, the weak learner is a decision stump:

The code above creates an instance of the DecisionTreeClassifier class from the scikit-learn library. By setting the max_depth hyperparameter to 1, the trained model will be a decision stump.
The magic of AdaBoost happens on line 8 of the above code, where the sample_weight parameter is used in the call to fit().
In this case, since all the weights are the same, the weights don't have much impact on the learning process for the decision stump. As you will see later, weights have a significant effect.
The following code visualizes the first weak learner in the ensemble:
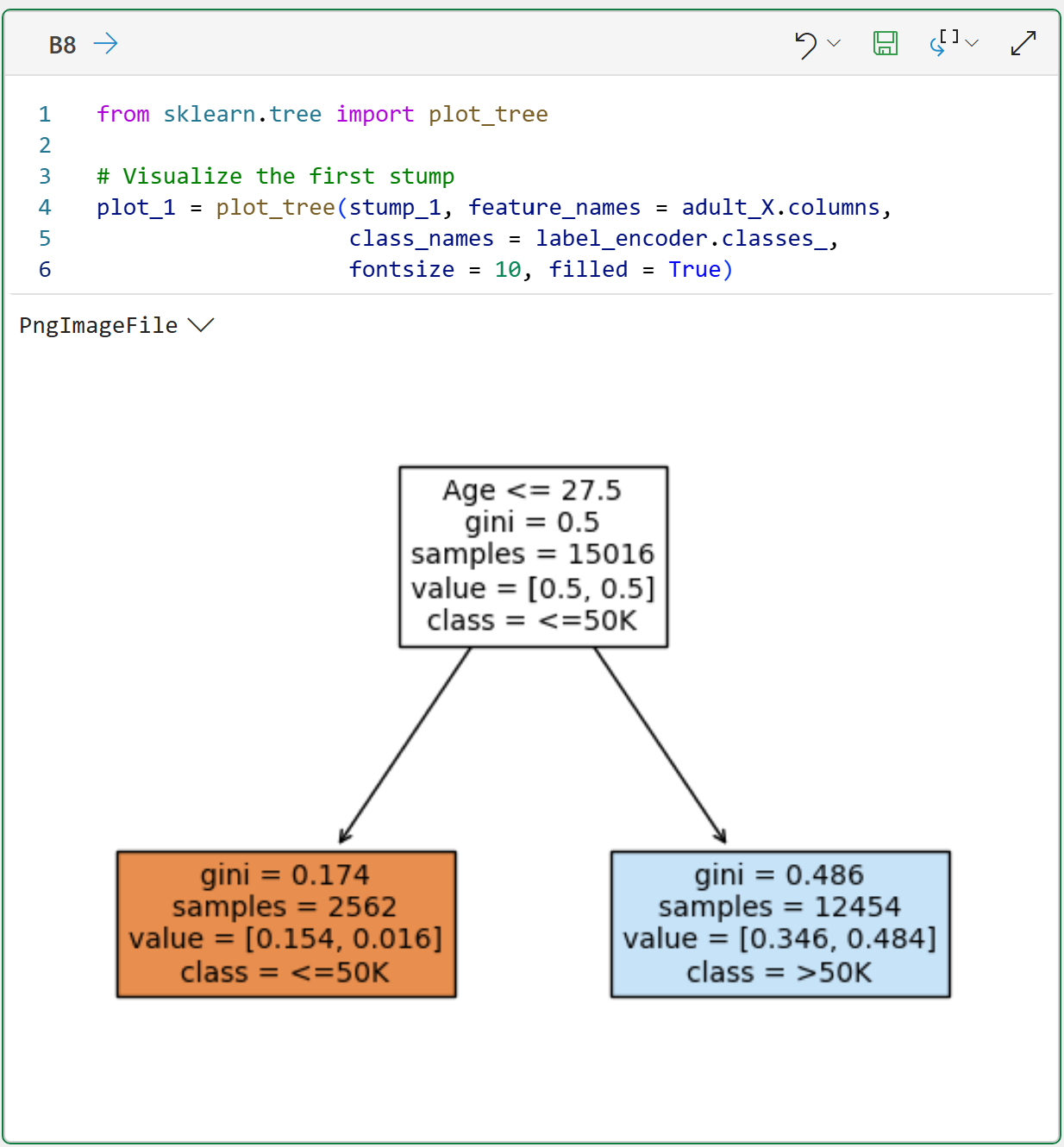
As shown above, the first weak learner in the ensemble has selected the rule Age <= 27.5 for making its predictions. Not surprisingly, this isn't very good in terms of its predictive performance (e.g., accuracy).
For example, dataset rows where Age > 27.5, the above decision stump model is only slightly better than 50/50 in making predictions.
Not to worry, outcomes like this are by design with the AdaBoost algorithm.
Boosting Round #2
With the first weak learner in place, the AdaBoost algorithm uses the predictions from the first decision stump to weight the data for the second boosting round.
The intuition here is that the weighting will make the next weak learner focus on the predictions the previous weak learner got wrong:

As covered in Part 2, think of the alpha as the importance score for the weak learner. Given that the first weak learner's error was less than 0.5 (i.e., 0.36228), it received a positive alpha score of 0.565481.
With the erroneous predictions identified and the first weak learner's alpha score calculated, AdaBoost then updates the dataset weights for the next weak learner to focus on better predicting the errors:
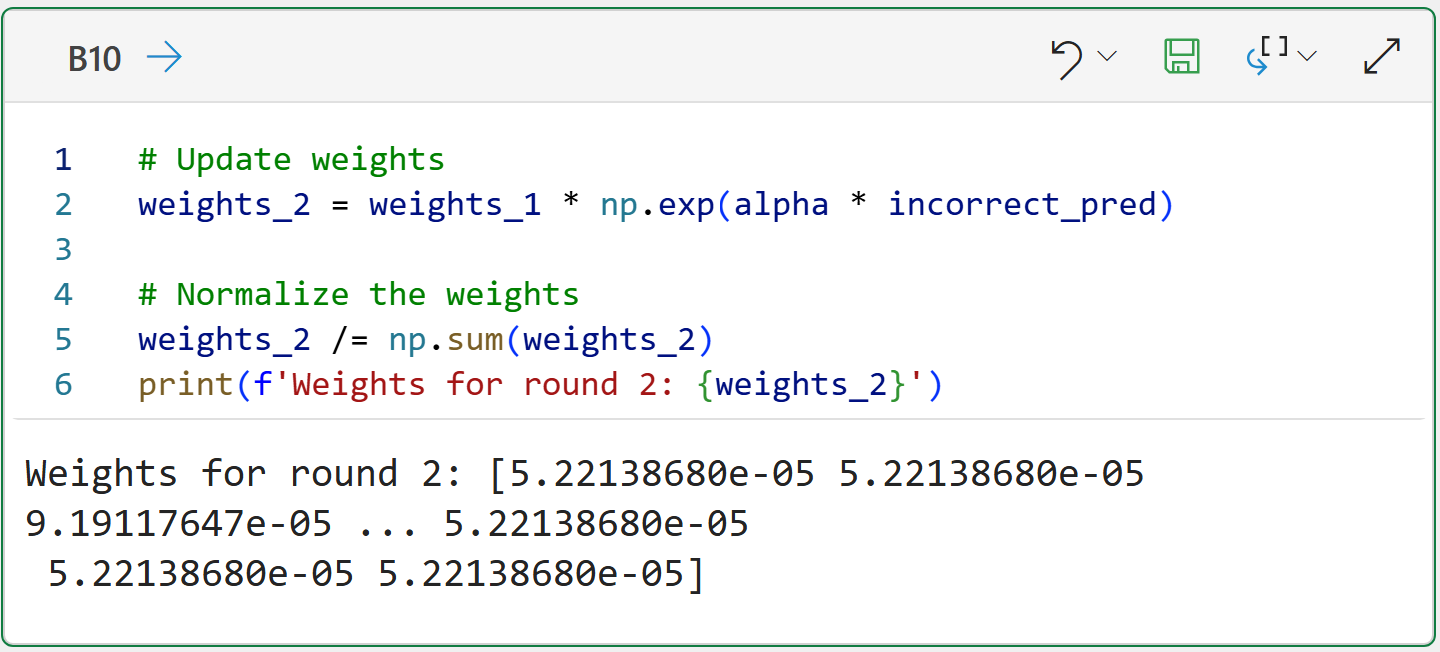
In the output above, take a look at the Round #2 weights and compare them to the Round #1 weights. In particular, compare the first three Round #2 weights to the first three Round #1 weights:
Round #2 weights:
5.22138680e-05
5.22138680e-05
9.19117647e-05
Round #1 weights:
6.65956313e-05
6.65956313e-05
6.65956313e-05
The Round #2 values illustrate how the weights are adjusted to give errors (e.g., the third row of the dataset) higher weights.
With the updated weights calculated, a second weak learner is added to the ensemble:
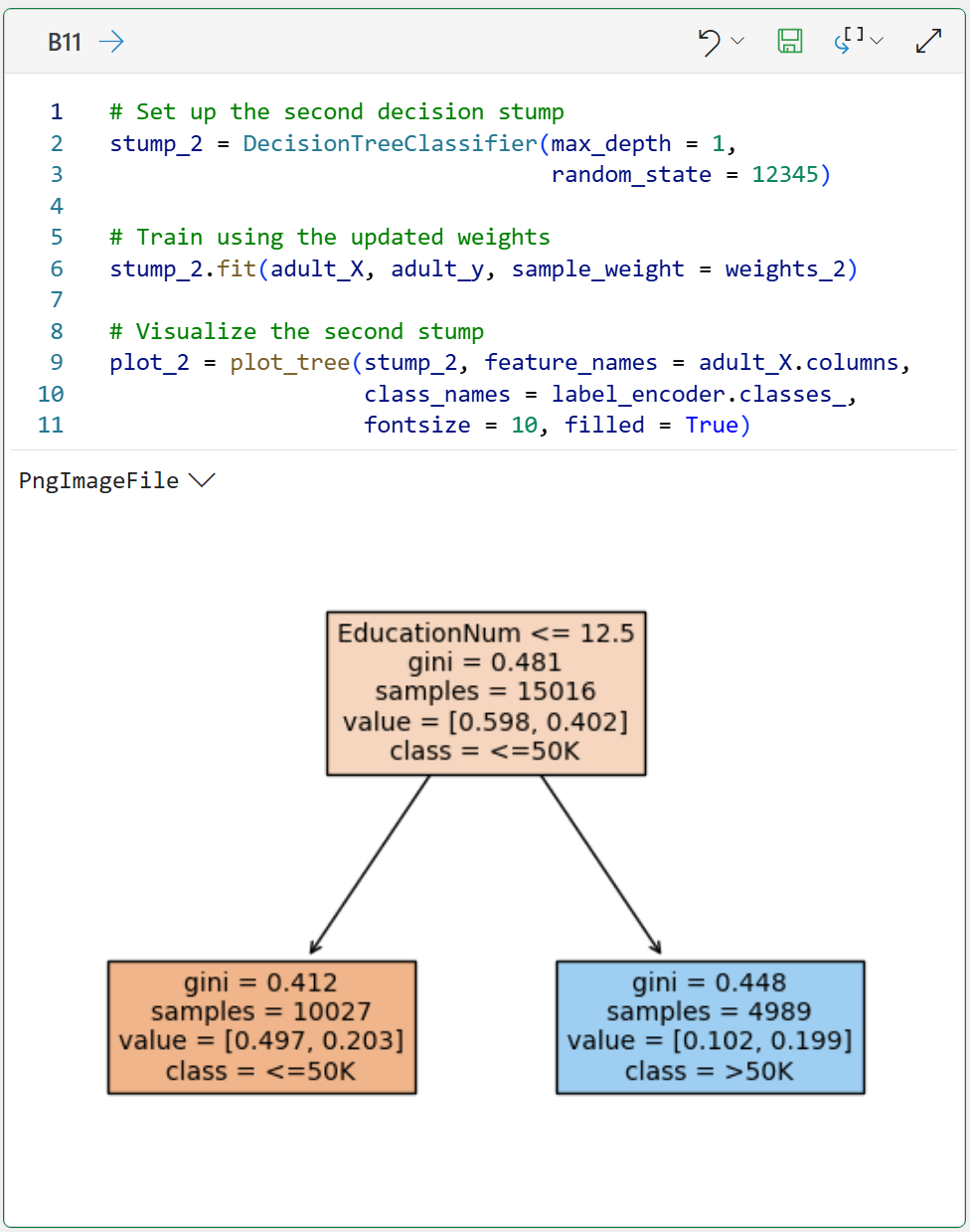
The above decision stump demonstrates the power of the AdaBoost algorithm.
Because of the changed weights, the second decision stump has focused on the EducationNum feature as the best way to address the errors of the first decision stump.
However, AdaBoost isn't done yet because we're assuming three boosting rounds.
Boosting Round #3
The same process is just repeated, starting with finding the errors for the second weak learner:
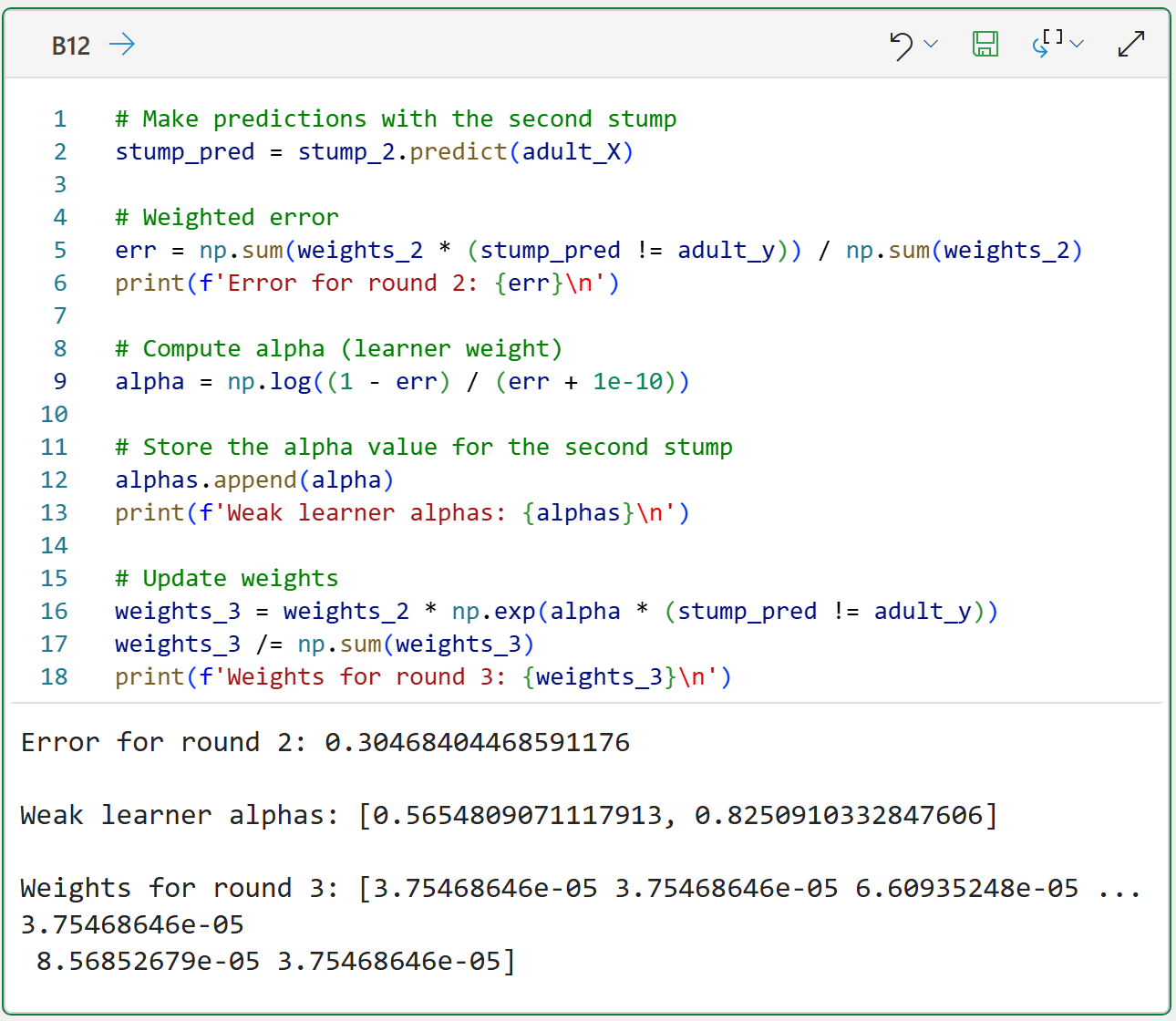
Check out the error and alpha for the second weak learner in the output above.
Because the second weak learner has a lower error than the first weak learner, it has a higher alpha score of 0.825091 compared to 0.565481.
As you will learn in the next tutorial, the second weak learner will be considered more important than the first weak learner in making predictions.
Again, with the weights updated, the final weak learner can be added to the ensemble:

Notice how the third decision stump has chosen the CapitalGain feature to address the errors of the second decision stump?
This is core to using machine learning ensembles: to achieve better predictive performance, the ensemble models should be significantly different from each other.
As you can see, the AdaBoost algorithm's use of weights and decision stumps ensures the models are as different from each other as possible.
And the alpha for the final weak learner:
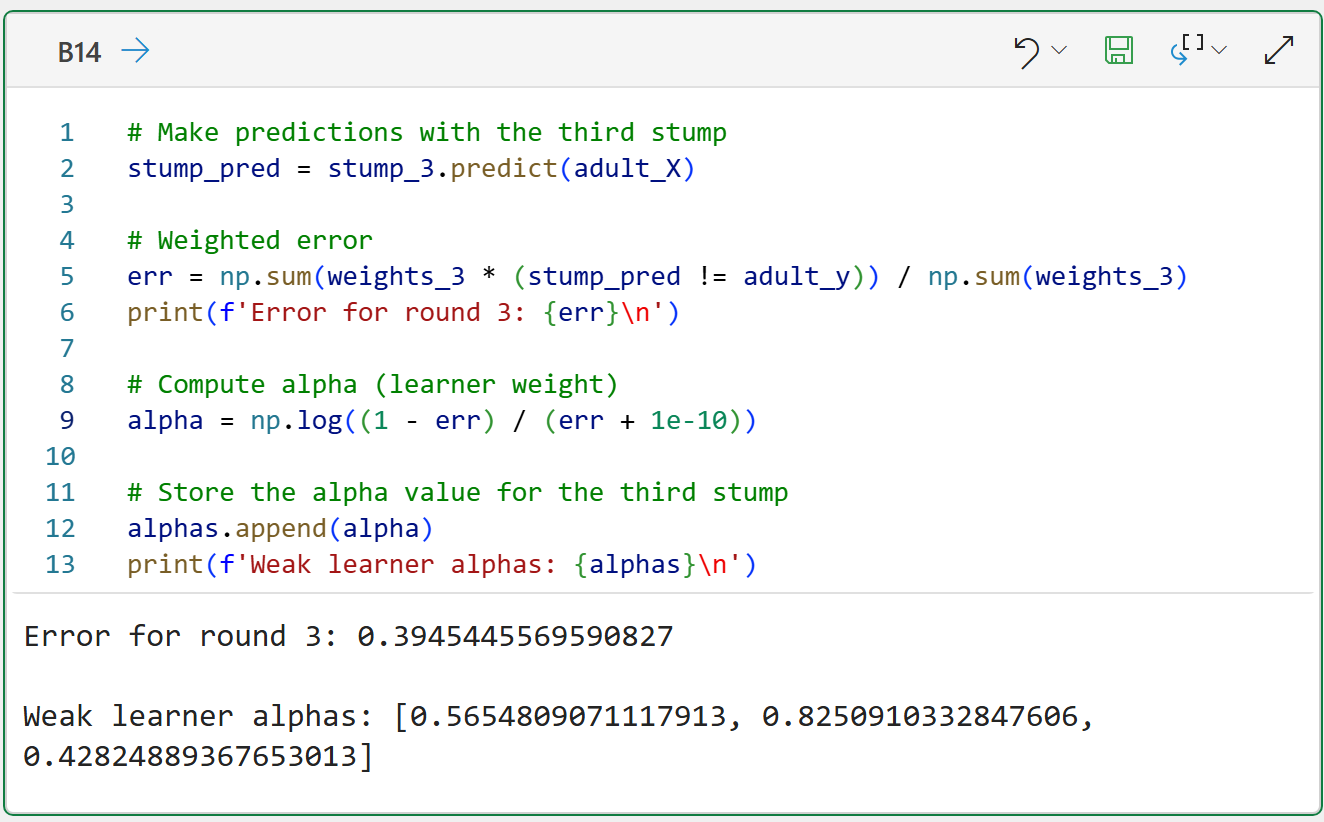
The above output for the third weak learner demonstrates an important concept in boosted decision tree machine learning.
Inevitably, there are diminishing returns for adding more models to the ensemble. In the worst-case scenario, adding too many models can reduce the predictive performance of the ensemble.
In the case of AdaBoost, tuning the ensemble model involves determining the optimal number of weak learners for a given dataset.
This Week’s Book
I've recommended this book several times in this newsletter, and I'll do so again. If you're interested in learning more about ML algorithms like AdaBoost, this is my favorite book:

This is a university textbook, but don't let that scare you away. It is very approachable because it doesn't include any code and isn't super math-heavy.
That's it for this week.
Next week's newsletter will cover how the AdaBoost algorithm combines all the weak learners to make better predictions.
Stay healthy and happy data sleuthing!

Dave Langer
Whenever you're ready, here are 3 ways I can help you:
1 - The future of Microsoft Excel forecasting is unleashing the power of machine learning using Python in Excel. Do you want to be part of the future? Order my book on Amazon.
2 - Are you new to data analysis? My Visual Analysis with Python online course will teach you the fundamentals you need - fast. No complex math required, and Copilot in Excel AI prompts are included!
3 - Cluster Analysis with Python: Most of the world's data is unlabeled and can't be used for predictive models. This is where my self-paced online course teaches you how to extract insights from your unlabeled data. Copilot in Excel AI prompts are included!