
Join 1,000s of professionals who are building real-world skills for better forecasts with Microsoft Excel.
Issue #24 - Machine Learning with Python in Excel Part 4: Data Visualization
This Week’s Tutorial
This week's issue is the fourth tutorial of a series demonstrating how Microsoft is positioning Excel as the DIY data science platform of the future.
This week's tutorial builds upon Part 3 of the series - be sure to check it out if you haven't already read it.
If you want to follow along by writing code (highly recommended), you can get the PythonInExcelML.xlsx workbook from the newsletter GitHub repository.
On to the tutorial...
Part 3 left off with the results of a common DIY data science scenario - segmenting data using cluster analysis.
In this case, the dataset is a classic marketing example - customer segmentation.
If you're not in marketing, don't worry.
Cluster analysis is one of the most widely used of all data science techniques. For example, the Copilot in Excel AI will often use cluster analysis to mine groupings from your data - regardless of your role or industry.
At the time of this writing, there's another reason why cluster analysis is such a valuable skill - cluster analysis is job security for humans.
While you can certainly use AI tools like Copilot in Excel to help you interpret the cluster analysis results, AI can't produce a full interpretation that will resonate with business stakeholders.
You still need a human in the loop.
So, today's tutorial will teach you how to use data visualizations to interpret a cluster analysis.
Luckily for us, Python in Excel supports the best data visualization library for DIY data science - the mighty plotnine.
BTW - If you like what you see in this tutorial, then my Visual Analysis with Python online course is for you.
Building on the last tutorial, the first step is to import the plotnine goodness we need:
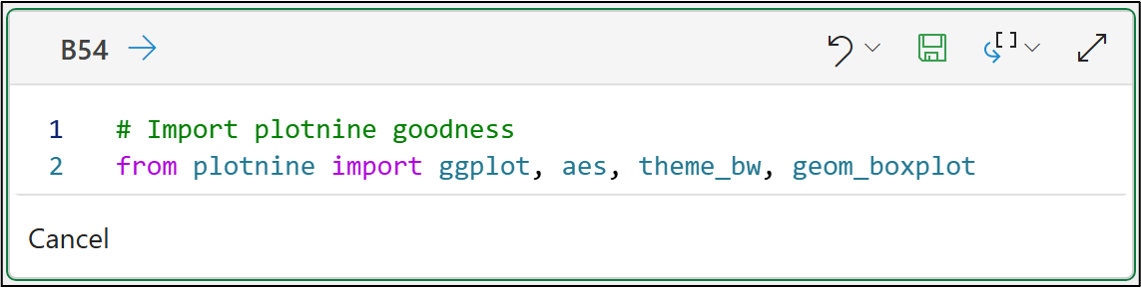
You can think of the above functions as being like what you need for creating a painting:
ggplot() is like the blank canvas.
aes() defines the paints you're using.
theme_bw() defines the style.
geom_boxplot() is the subject.
Not surprisingly, we start with the canvas and provide it with our dataset:
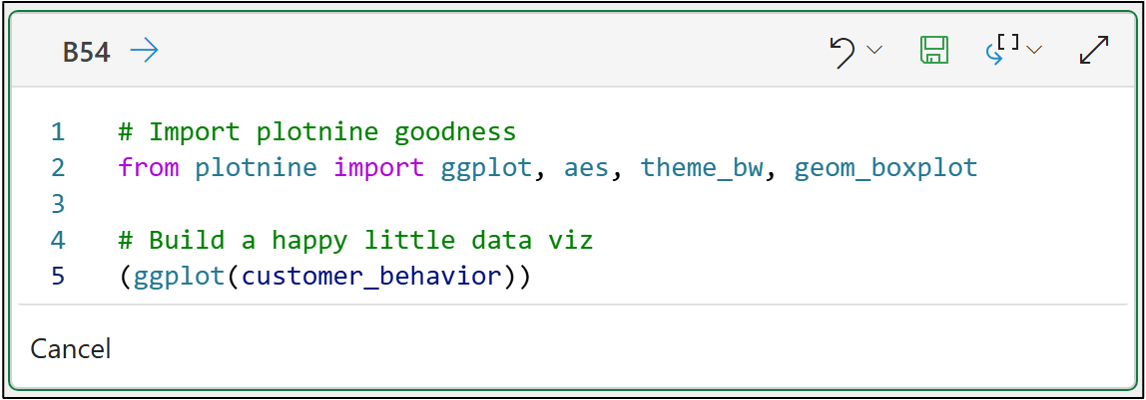
The code above demonstrates something critical in cluster analysis:
Always interpret your clusters using the original data. For example, scaled data will not be understood by your business stakeholders.
Passing the customer_behavior dataset to the ggplot() function provides the raw materials we need for our painting.
Next, we use aes() to define the paints.
But, before we can do that, we need to add the cluster assignments to the original data to use in the painting:
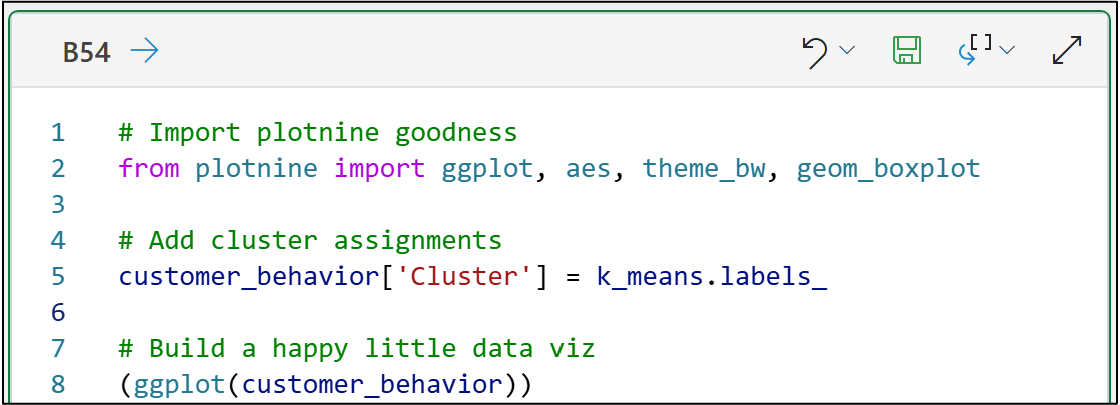
As you learned in the last tutorial, the cluster assignments are simply the numbers 0, 1, 2, and 3.
The clustering algorithm (i.e., k-means) has no idea what these assignments mean in real-world business terms. This is where you add value to the process.
Python technically "sees" the cluster assignments as numbers, when in fact they are categories.
We can take this into account when we define the paints using aes():
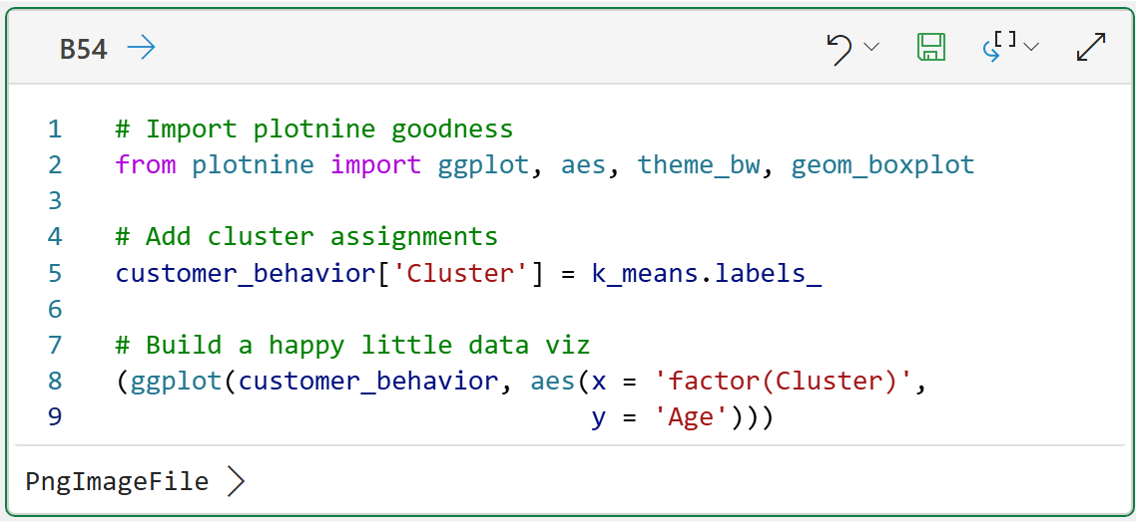
I've broken the call to the aes() function over two lines to demonstrate a couple of things:
The paints to use (i.e., the Cluster and Age features).
Using factor() to tell plotnine to treat Cluster as categorical data.
With the canvas and paints defined, we can now add in the style (i.e., theme) of the painting:
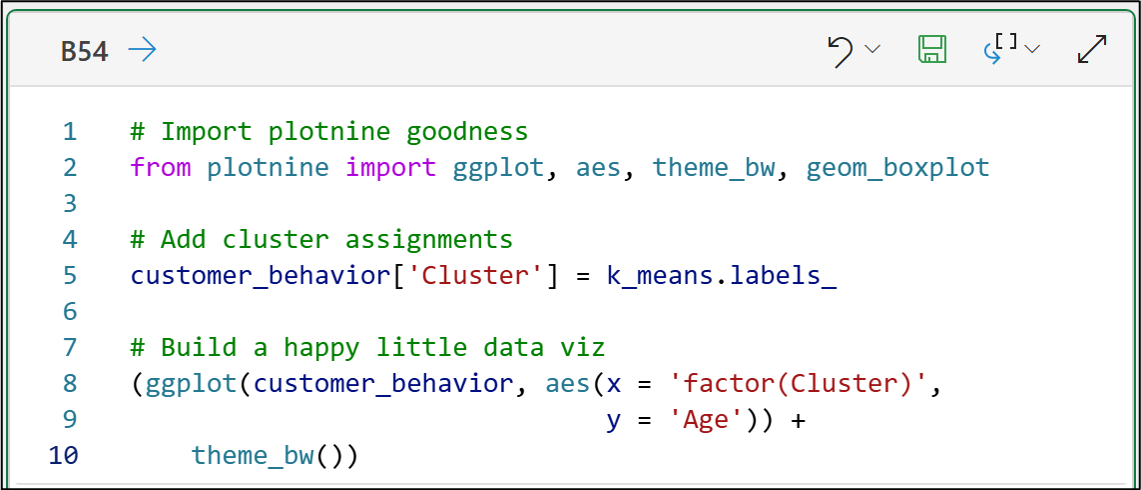
The theme_bw() function gives the painting a simple black and white theme.
When creating visualizations for data analysis, you typically want minimal colors as they are more distracting than helpful.
Next, we define what we want to paint. In this case, a happy little box plot:
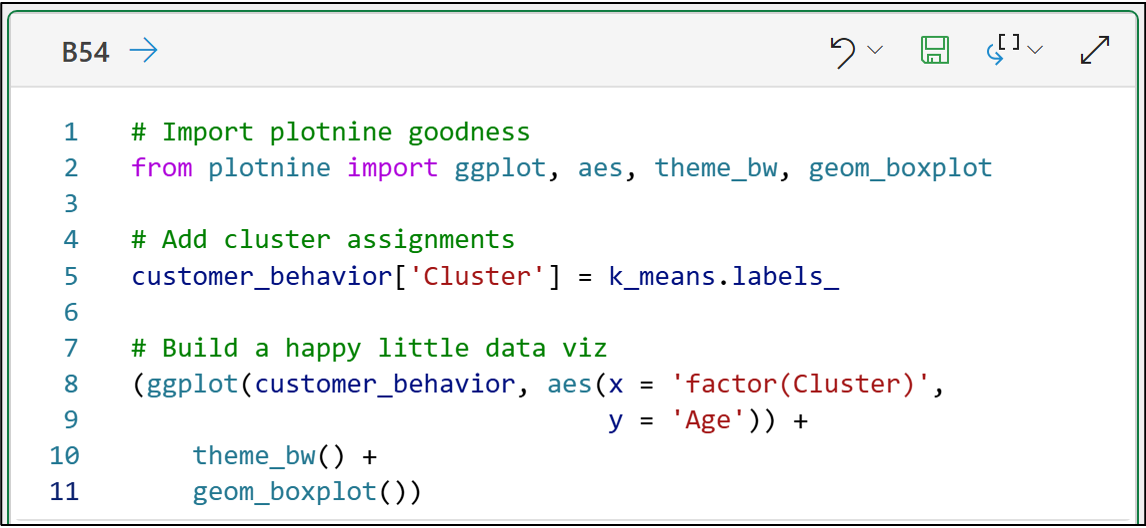
Notice the plus (i.e., +) symbols in the code above?
Think of the plusses as telling plotnine that you would like to add layers to the painting:
ggplot() is the canvas (base layer).
theme_bw() is layered on top of the canvas.
geom_boxplot() is layered on top of the theme.
This layering approach makes using plotnine to build your visualizations very intuitive.
When creating data visualizations with Python in Excel, it's usually most convenient to output the visualization to the worksheet:

And voila! A happy little box plot:

To see the above in the worksheet, be sure to right-click on the cell and select:
The box plot shows the distribution of customer Ages by their cluster assignment. In general, the Ages are similar across clusters, with Ages typically being a bit higher for clusters 2 and 3.
If you're unfamiliar with how to analyze data using box plots, my Visual Analysis with Python online course will teach you how.
When you're done looking at the visualizations, select Undo (e.g., ) to remove the reference.
One of the things that makes plotnine so great for DIY data science is how quickly you can create new visualizations.
For example, we can copy the above code, paste it into a new Python formula cell, and tweak it to look at the Income feature in a matter of seconds:

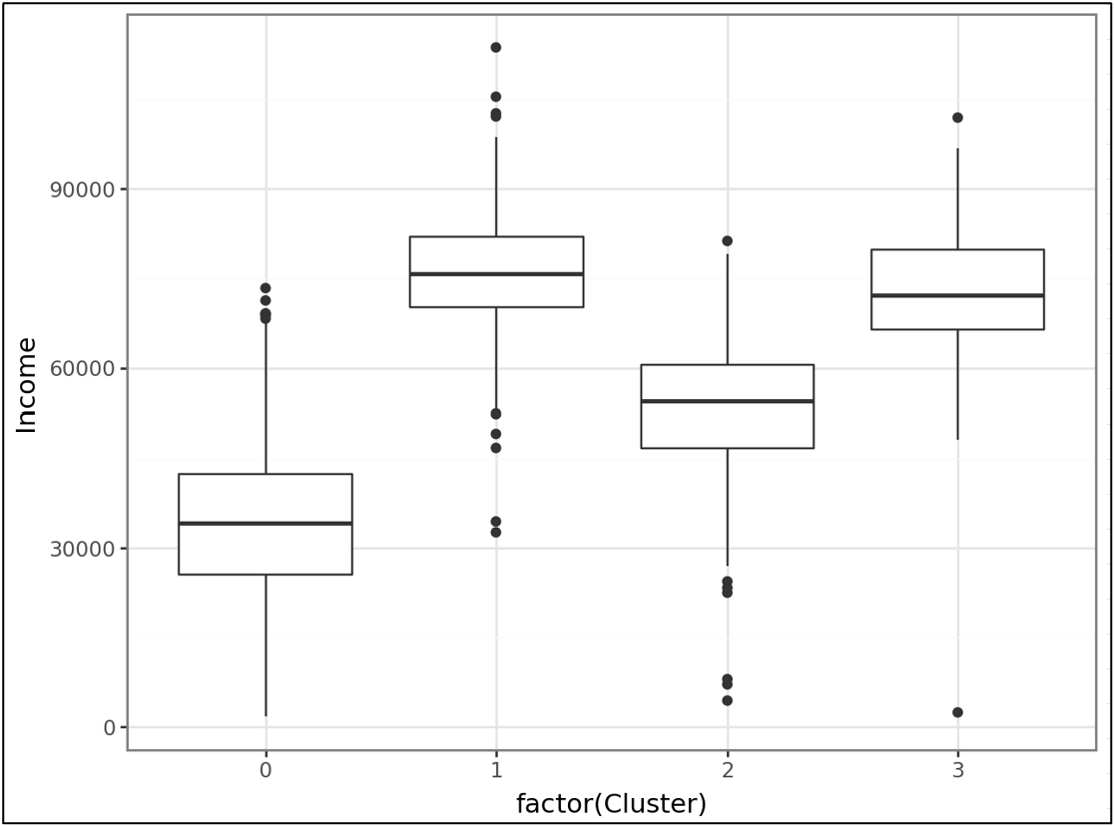
The above visualization shows an important interpretation of the clusters:
Clusters 1 and 3 have the highest Incomes.
Cluster 2 has lower Incomes than clusters 1 and 3.
Cluster 0 has significantly lower Incomes than the other clusters.
Using copy-and-paste reuse, it's easy to explore each of the features using box plots to build the interpretations of the clusters in business terms.
A more advanced analysis is to explore correlations between features by cluster.
Your go-to visualization for correlation analysis is a scatter plot:
The code above adds two new functions into the mix:
geom_point() is how you create scatter plots.
facet_grid() is why plotnine is my go-to data visualization library.
You can think of facets as the means to create "mini-visuals" based on the unique values of a feature.
Facets are what make plotnine, IMHO, the best data visualization library for DIY data science.
The above code creates a scatter plot (i.e., a geom_point()) for every unique value of the Cluster feature:

The above faceted scatter plot shows the following correlations between Age and Income:
A strong positive correlation for cluster 0.
A weak positive correlation for cluster 1.
A moderate positive correlation for cluster 2.
A weak negative correlation for cluster 3.
Once again, you can quickly evaluate the correlations between features using copy-and-paste reuse of your plotnine code.
Visual data analysis is powerful way to interpret the results of a cluster analysis in terms that your business stakeholders can understand.
If distribution analysis (e.g., box plots) and correlation analysis (i.e., scatter plots) is new to you, my Visual Analysis with Python online course will teach what you need to know.
This Week’s Book
The mighty plotnine library is a Python port of the ggplot2 library from the R programming language. The definitive guide to ggplot2 is this free online book, and is a great resource to learn more about visual data analysis:

While the above book is written using the R programming language, this isn't a problem for two reasons:
The plotnine port is very good. The code looks almost exactly the same (e.g., function and parameter names).
With tools like ChatGPT, you can have the AI translate any R code into Python for you in seconds.
That's it for this week.
Next week's newsletter will demonstrate using Python in Excel to conduct powerful visual data analyses to interpret the clusters found in today's tutorial.
Stay healthy and happy data sleuthing!

Dave Langer
Whenever you're ready, here are 3 ways I can help you:
1 - The future of Microsoft Excel forecasting is unleashing the power of machine learning using Python in Excel. Do you want to be part of the future? Order my book on Amazon.
2 - Are you new to data analysis? My Visual Analysis with Python online course will teach you the fundamentals you need - fast. No complex math required, and Copilot in Excel AI prompts are included!
3 - Cluster Analysis with Python: Most of the world's data is unlabeled and can't be used for predictive models. This is where my self-paced online course teaches you how to extract insights from your unlabeled data. Copilot in Excel AI prompts are included!