
Join 1,000s of professionals who are building real-world skills for better forecasts with Microsoft Excel.
Issue #32 - Boosted Decision Trees Part 1:
Introduction
This Week’s Tutorial
When it comes to real-world predictive models, you usually can't go wrong with using some form of decision tree machine learning. Here's an example of a relatively simple decision tree:
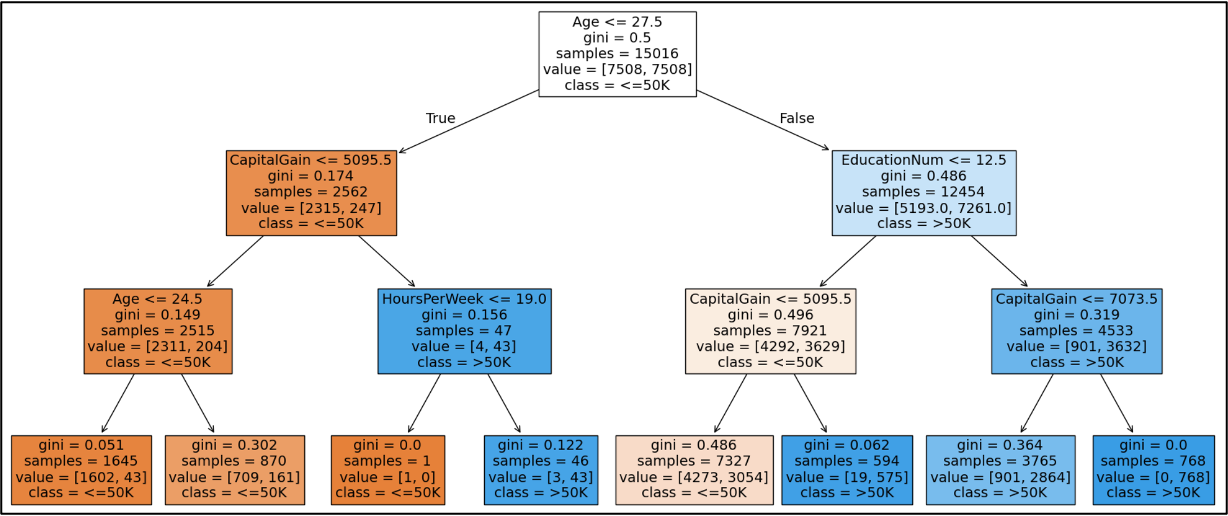
Here's why decision tree machine learning is useful to any professional.
Most business data comes in the form of a table. Some common examples:
Database tables
Excel tables
CSV files
Not only is most business data tabular, but it is also structured. The easiest way to think about structured data is by way of comparison.
Imagine a column of data containing string values for Olympic medals (i.e., None, Bronze, Silver, and Gold) or a column containing shipping dates for orders. These are both examples of structured data.
Now imagine a column of data containing free-form text of customer services chats. Something like:
I have a question regarding my last bill. I was promised a discount for renewing my service and it was not applied to my account.
Free-form text is the most common type of unstructured business data.
When your data is tabular and structured, decision tree-based machine learning is state-of-the-art and a great place to start your predictive modeling.
Given how useful decision tree machine learning (ML) is for real-world applications, it shouldn't surprise you that a lot of research has gone into making decision tree ML as effective as possible.
Decision Tree Ensembles
One of the most powerful ways of making decision tree ML more effective is a relatively simple idea - combining multiple decision tree models.
This technique is known in ML as ensembling and is very intuitive.
Simply put, ensembling combines the predictions of multiple different ML models. When done well, ensembles of ML models provide better and more consistent predictions compared to using a single ML model.
Over the years, two forms of decision tree ensembles have become very popular due to their usefulness in broad range of business scenarios:
Random forests
Boosted decision trees
While both of these ensembling techniques (i.e., algorithms) use collections of decision trees models to work their predictive magic, each takes a different strategy for building (i.e., training) the trees in the ensemble.
This tutorial series will teach you about boosted decision trees. Specifically, the Adaptive Boosting (or AdaBoost) algorithm.
If you're familiar with ML, you might have heard of the following popular boosted decision tree algorithms:
XGBoost
LightGBM
CatBoost
If this is the case, you might be wondering why this tutorial series covers AdaBoost instead. Here's why.
Compared to these other algorithms, AdaBoost does not require complex math. This allows you to focus on why boosted decision trees are so powerful.
Boosted Decision Tree Intuition
The best way to build machine learning skills is to first develop an intuition by using a metaphor. In the case of boosted decision trees, I'm going to use the metaphor of a tutor.
Imagine that you've hired a highly-recommended tutor to help improve your learning of a specific subject. This tutor has a proven process for helping their clients (e.g., you):
They assess a client's knowledge of the subject (e.g., via a quiz).
Based on the assessment, the tutor prioritizes the areas where the client's knowledge needs to be improved.
The client studies the prioritized areas.
This process repeats (i.e., starts again at 1) until the client has "mastered" the subject.
You can think of the AdaBoost algorithm as the tutor, using a process like the one listed above.
While this is more abstract, think of each decision tree as the client learning more with each iteration:
Tree #1 learns from the dataset, getting some things wrong.
Tree #2 prioritizes learning from Tree #1's mistakes.
Tree #3 prioritizes learning from Tree #2's mistakes.
And so on, until the ensemble "masters" the data.
In this case, by "master", I mean that the quality of the ensemble's predictions is no longer improving enough, and AdaBoost stops training new decision trees.
At the end of this process, AdaBoost has trained many decision trees, where each of these tree models is known as a weak learner.
Weak Learners
In machine learning, a weak learner is a fancy way of saying that a model is simple. The simplest (i.e., weakest) decision tree is know as a decision stump.
Decision stumps are weak learners because they ask only a single question of the data to make a prediction.
Here is an example of a decision stump that predicts the yearly salary of US residents.
BTW - This tutorial series will be using the adult_train.csv and adult_test.csv data sets available from the newsletter repository:
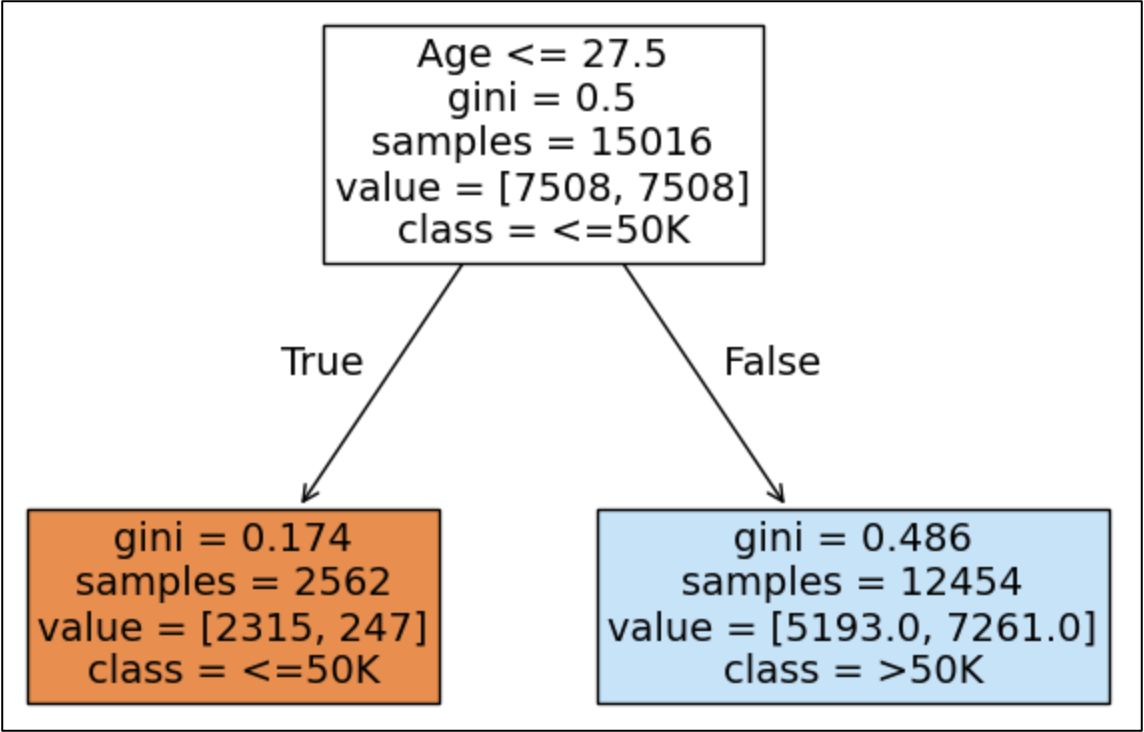
In natural language, here's how to interpret the above decision stump:
"If a person's age is less than 28 years old, the model predicts an income of less than or equal to $50,000 per year. Otherwise, the model predicts an income of greater than $50,000 per year."
Even without seeing the dataset or knowing a lot about the US economy, it's easy to understand that this model is weak - it hasn't learned enough patterns from the data to make good predictions.
Here are two examples of what this weak learner has not learned:
There are many US residents over 28 years old who make less than $50,000 per year.
There are many US residents under 28 years old who make more than $50,000 per year.
If this were the only predictive model, this would be a huge problem, but remember that AdaBoost builds an ensemble of weak learners.
So, AdaBoost trains another decision stump where the new decision tree prioritizes the errors of the first tree. Let's say this is the resulting 2nd weak learner:
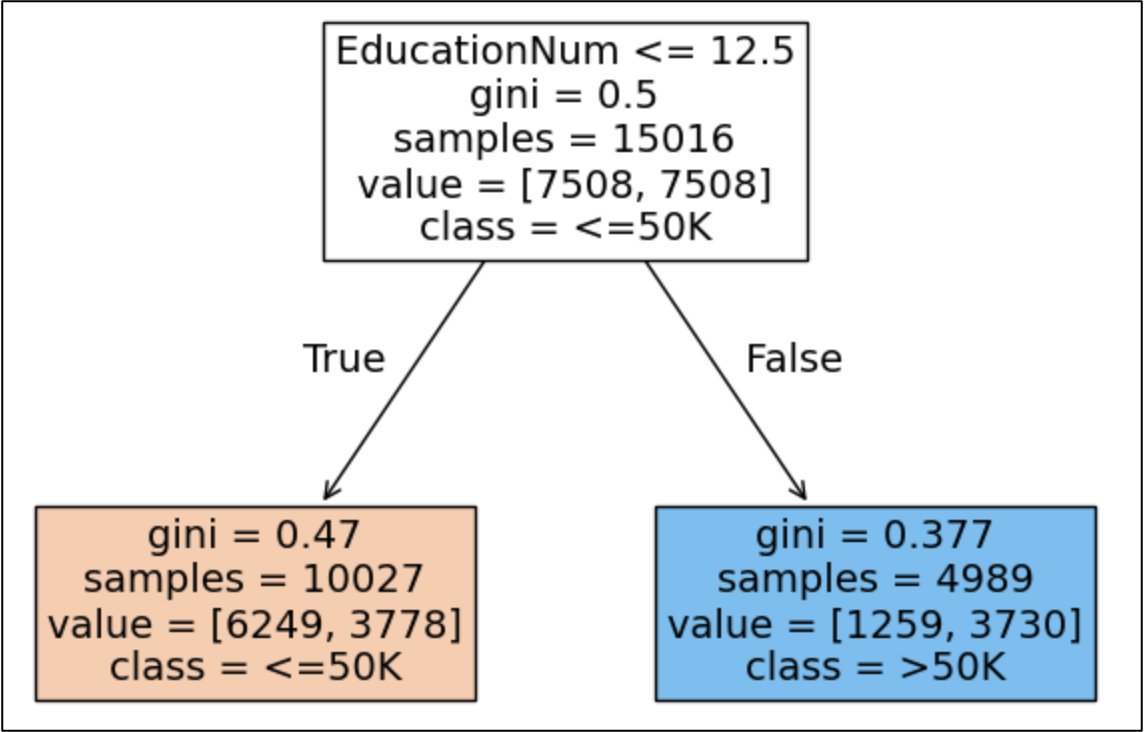
Notice how the 2nd decision stump asks a different question before making a prediction?
This illustrates the magic of AdaBoost - by prioritizing the mistakes of the previous weak learner, new weak learners are almost always different from previous weak learners.
This has the effect of AdaBoost learning different aspects of the data. Later in the tutorial series, you will learn how AdaBoost combines all of these decision stumps to create accurate predictions.
This Week’s Book
If you're looking for a book on decision tree machine learning, this week's book is as definitive as a resource as you can get:

I'm going to be completely honest here. This book is jam-packed with mathematics. If you're into that sort of thing, this book is for you. If math isn't your thing, please wait for next week's book recommendation. 🤣
That's it for this week.
Next week's newsletter will begin diving into how the AdaBoost algorithm works behind the scenes to build powerful ensembles of decision stumps.
Stay healthy and happy data sleuthing!

Dave Langer
Whenever you're ready, here are 3 ways I can help you:
1 - The future of Microsoft Excel forecasting is unleashing the power of machine learning using Python in Excel. Do you want to be part of the future? Order my book on Amazon.
2 - Are you new to data analysis? My Visual Analysis with Python online course will teach you the fundamentals you need - fast. No complex math required, and Copilot in Excel AI prompts are included!
3 - Cluster Analysis with Python: Most of the world's data is unlabeled and can't be used for predictive models. This is where my self-paced online course teaches you how to extract insights from your unlabeled data. Copilot in Excel AI prompts are included!